Paper reading-Ask in Any Modality A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
RAG 抽象来说就是,embed - opitional[rerank] - generate管道
有许多的增强方案,例如 Plan X RAG(将问题分解为子问题的DAG,然后设计一些critic LLM判断流的状态正常与否,一个执行LLM按照拓扑序执行DAG),Agentic RAG, feedback-driven iterative refinement
局限是:传统RAG主要针对文本,多模态集成还是挑战
流程概述如下图

Multimodel RAG
LLM拓展为MLLM带来了多模态RAG的挑战
- 检索哪些模态
- 数据类型的有效融合
- 跨模态相关性
特定模态的编码器将不同的模态映射到共享语义空间,实现跨模态对齐
现有数据集和基准
数据集
-
图文任务(字幕、检索):MS-COCO, Flickr30K, LAION-400M
-
利用外部知识的视觉问答: OK-VQA
-
多模态推理:MultimodalQA
-
视频文本任务:ActivityNet,YouCook2
-
医学:MIMIC-CXR
许多数据集都是单模态的,随后与其他模态的互补数据集集成。
Benchmark
: 我们执行以下步骤来处理图像,以确保它们具有高质量并且与用户查询相关: (1)缓存和转换:使用 URL 下载所有图像,并将其转换为广泛接受的格式,例如 JPG、PNG、GIF 或 WEBP。无法成功下载或转换的图像将被丢弃; (2)过滤:小于某个阈值或与查询文本的基于 CLIP 相似度得分较低的图像将被删除。此类图像通常包含非代表性的视觉内容,例如图标、横幅等。 (3)重复数据删除:使用 PHash Zauner 算法删除重复或高度相似的图像。
指标设计:主要靠prompt gpt-4o做评估
- 文本模态指标:流畅性,相关性,忠实度,上下文准确率
- 多模态指标:图像连贯性(图像和周围文本逻辑的连贯性,图像有用性, 图像引用(验证图像和文本引用的适当性),图像召回率(高度相关图像的召回比例)
- 取所有指标的平均值用于��计算总分
两种联合建模策略
- single-stage:直接生成多模态输出
- multi-stage: 文本生成 - 图像插入 - 文本重润色 三个阶段


视觉为中心的评估
MRAG-Bench, VQAv2, VisDoMBench, Dyn-VQA, ScienceQA
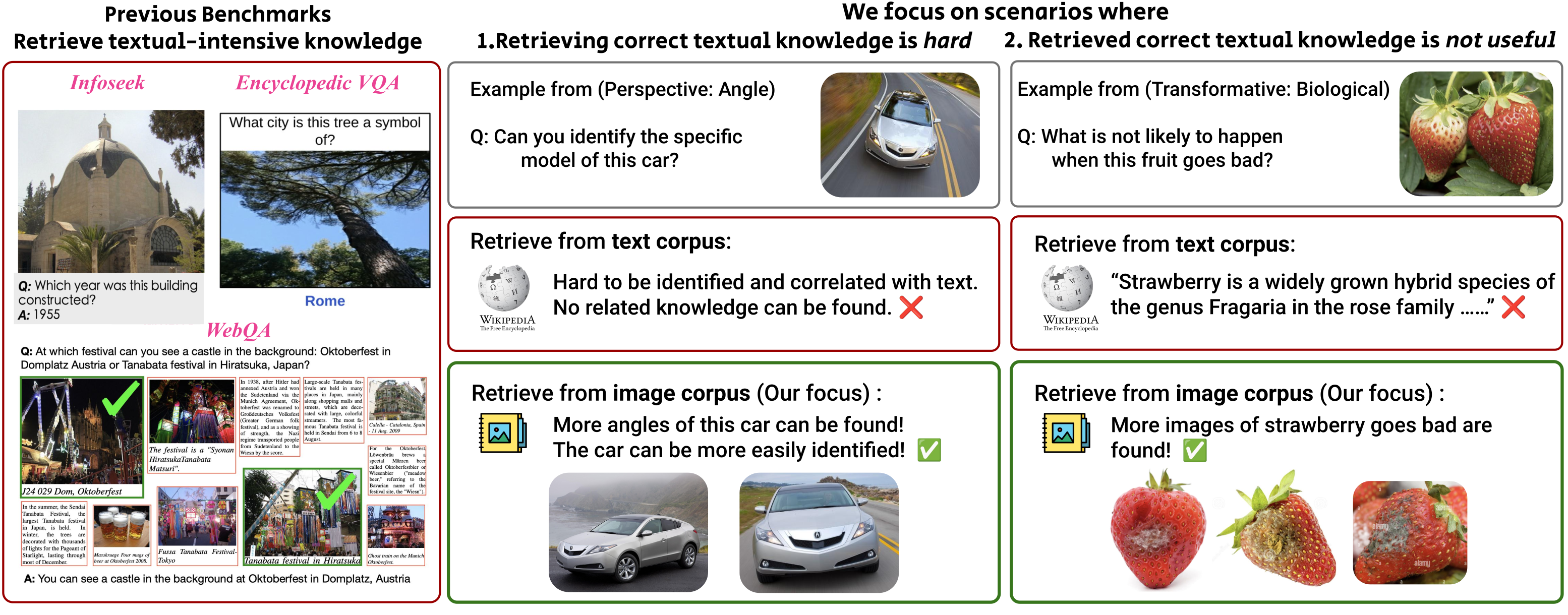
知识密集型评估
TriviaQA, RAG Check, Natural Questions
创新和方法
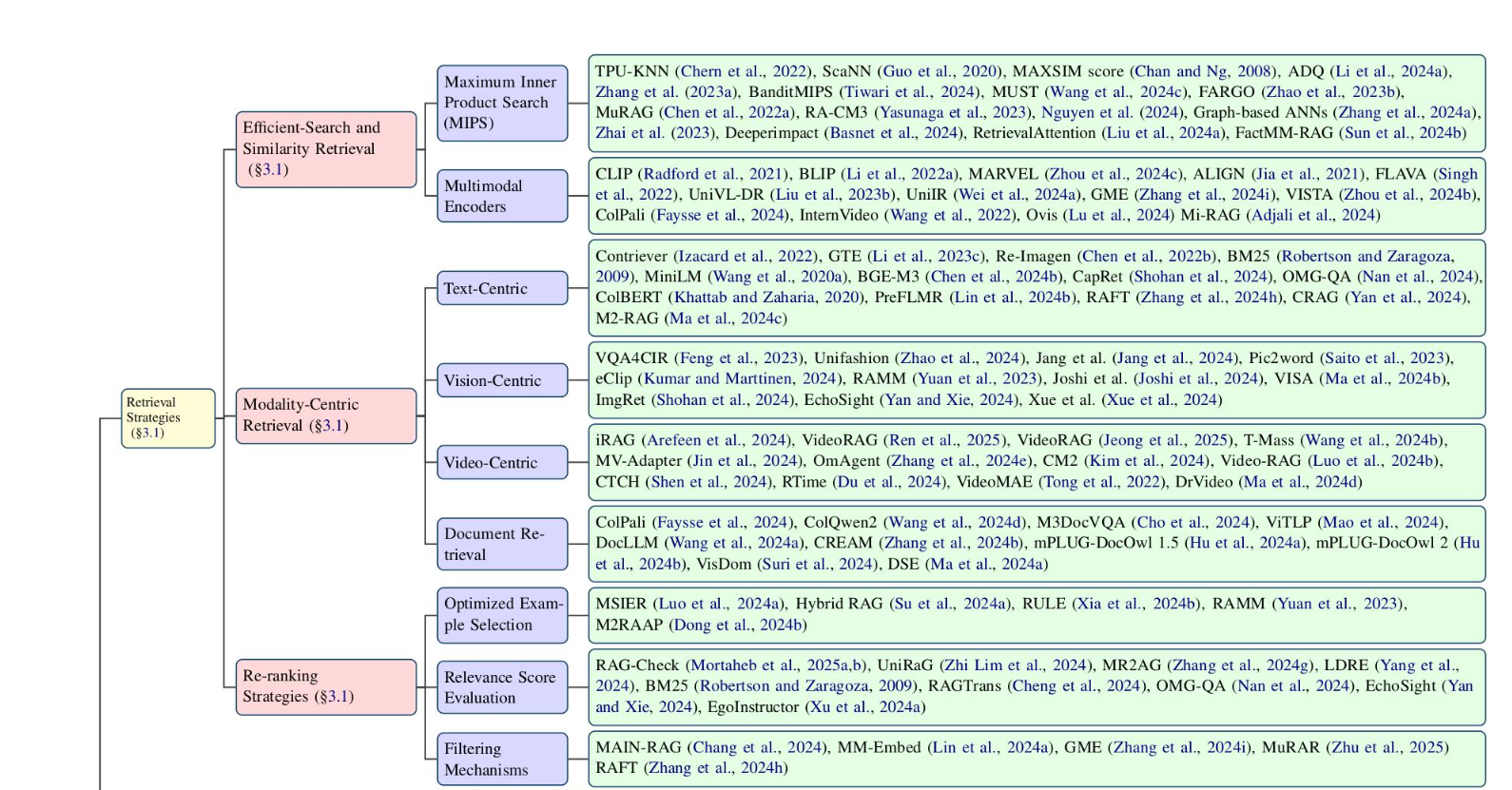
检索策略
高效和精度
现代MRAG将不同输入模态编码到统一的embedding空间实现直接跨模态检索
方法上,主要为Maximum inner product search (MIPS) 变体:近似MIPS,分布式MIPS,KNN变体,近似KNN,ScaNN
- ScaNN主要结合了一些数学方法 和 量化方法构建了足够快的向量检索索引,这类方法都是用于海量数据的(如1M)
- 专注于CPU,例如做了很多量化优化让它能尽量利用现代CPU的simd指令 https://zilliz.com/blog/faiss-vs-scann-choosing-the-right-tool-for-vector-search
创新主要在效率提升和精度降低:
- 混合搜索
- 自适应量化
- learned index: 神经网络驱动的索引建立,主要是数据库那边的工作
以模态为中心的检索
文本中心
- BM25
- bge-m3
- ColBERT
- RAFT(混合干扰和ground truth文档微调模型增强抗干扰能力)
- ...
视觉中心
- 直接用图像表示进行知识提取
- 基于参考图像的检索,如EchoSight和ImgRet
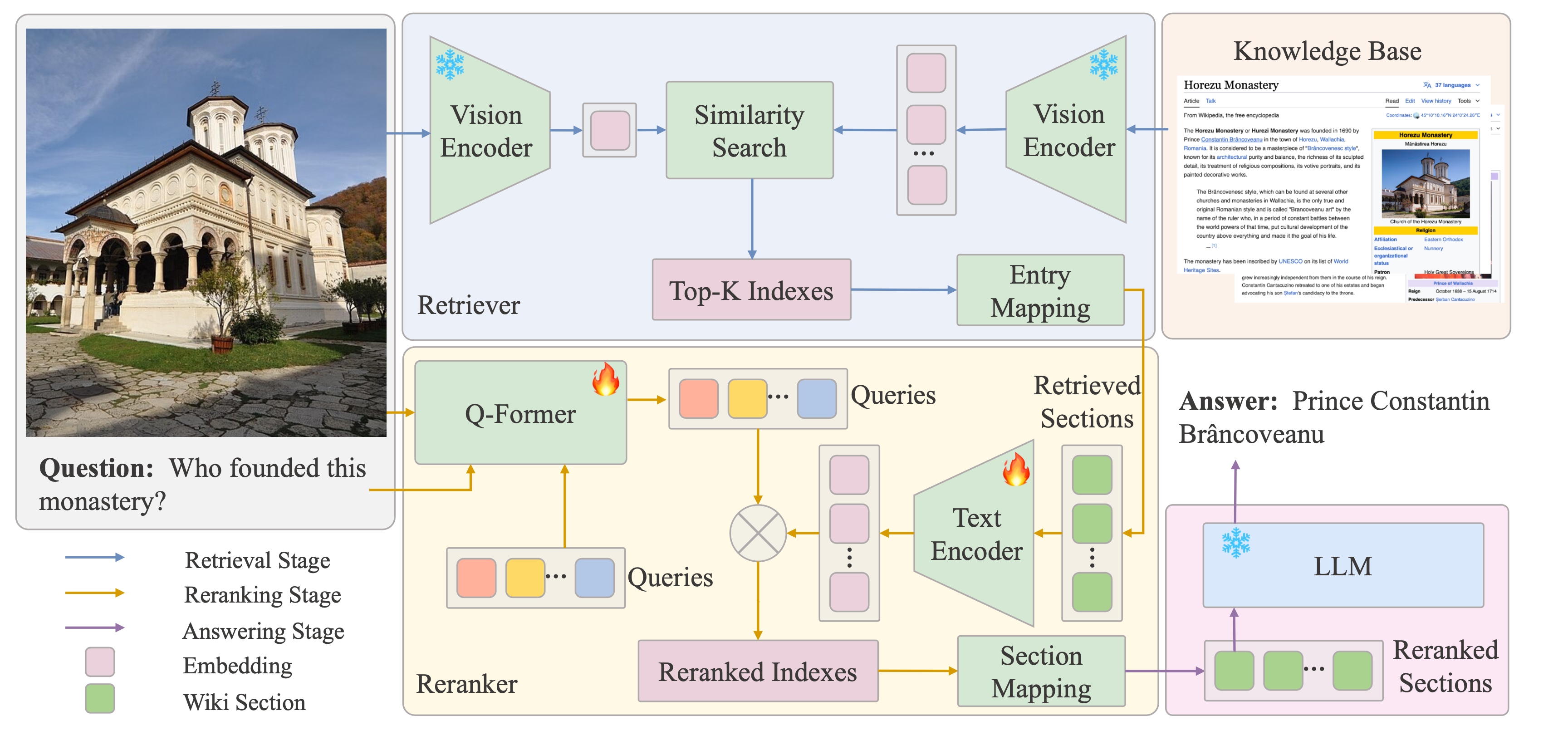
- EchoSight 引入了多模态重排
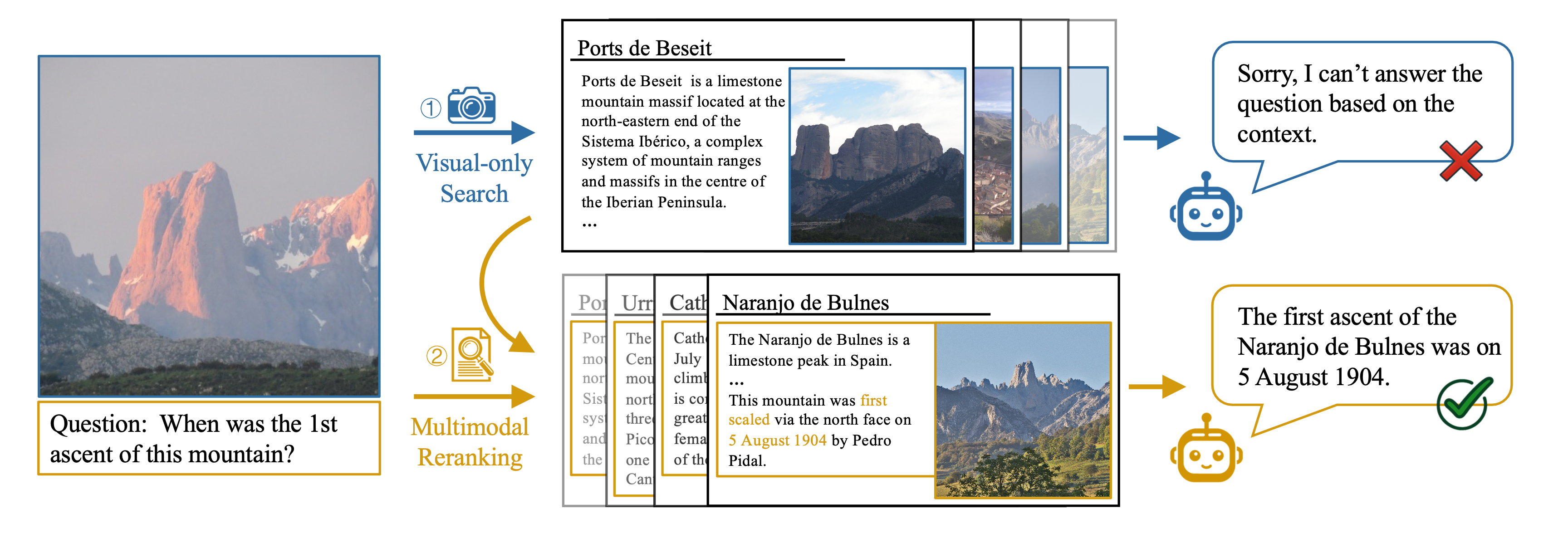
具体来说,对于一个图文问题query, 先用image视觉相似度找到对应的wiki条目,再将wiki的section与图+文的完整query(经过Q-Former之后)进行文本rerank,最后综合视觉分数和文本rerank分数,选取topk后输入LLM。专注于问题和知识库都是图+文的情况,也只是finding, 感觉确实创新度不够
- 组合多张图像特征形成综合查询表示
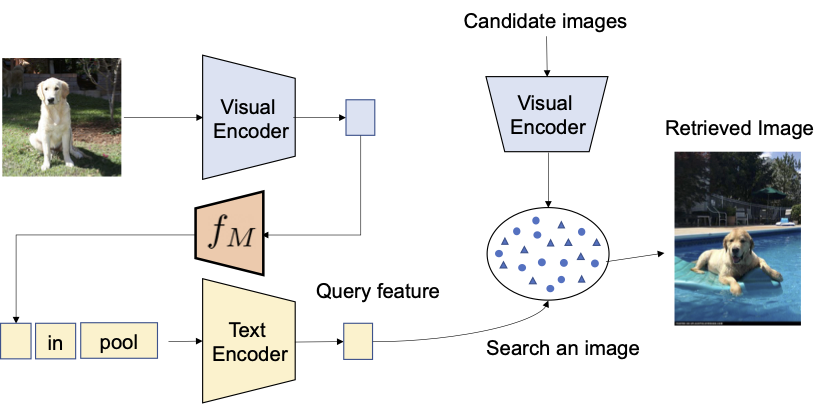
- 图文映射:Pic2word 如下图,将视觉映射到文本描述
视频中心
- iRAG,增量检索
- MV-Adapter
- Video RAG
- RTime: 时间因果关系
- OmAgent:分治处理复杂视频理解
- DRVideo:基于文档检索处理长视频理解
- ...
文档检索和布局理解
ColPali, ColQwen2: 端到端文档图像检索,动态分辨率处理,整体多页推理,绕过OCR技术,1.9k star
它的想法是这样的
- OCR的多个组件和分块带来误差传播,且预处理流程耗时也长,能不能直接端到端一次使用文档截图解决
- 但是如果将整页的文档编码成一个向量,肯定精度不够
- 多向量�方案最经典的ColBERT, 并且在这样一个视觉的情况下,视觉patch做多向量比文本token还合理
- 贡献
- benchmark ViDoRe
- 将ColBERT和视觉语言模型结合,利用多向量不仅启发了文搜文,文搜图,还启发了“给一个文档,查找相似的文档”这样的任务
- 提供了一个良好的视觉文本融合的范式(例如,解决了CLIP这样的模型缺乏文本细粒度的问题),允许最先进的VLM如Qwen-VL-2B,以相同的训练策略微调后作为嵌入器,+5.3 nDCG@5

可不可以将这个范式沿用到引用溯源?
已经有一些了,ColPali自己就做了每个词条最显著的图像块

一些布局理解的新框架:ViTLP, DocLLM, CREAM, mPLUG-DocOwl
To our knowledge, no benchmark evaluates document retrieval systems in practical settings; in an end-to-end manner, across several document types and topics, and by evaluating the use of both textual and visual document features.
https://huggingface.co/blog/fsommers/document-similarity-colpali 基于 OCR 的文本提取,以及随后的布局和边界框分析,仍然是重要文档 AI 模型(例如 LayoutLM)的核心。例如, LayoutLMv3 对文档文本进行编码,包括文本标记序列的顺序、标记或线段的 OCR 边界框坐标以及文档本身。这在关键的文档 AI 任务中取得了最佳成果,但前提是第一步——OCR 文本提取——能够顺利完成。
但通常情况并非如此。
根据我最近的经验,OCR 瓶颈导致现实世界生产文档档案中的命名实体识别 (NER) 任务的性能下降近 50%。

为下游任务提供了一系列微调版本
- Image Caption 加字幕
- VQA
- Detection (Detect [entity])
- 图像实体分割
- 文档理解
重排序和选择
多用多步骤检索,整合监督和非监督策略
- probabilistic control keywords to improve credibility
- 对示例的关键信息进行关键词提取,为关键词赋予概率权重,使用概率进行控制信号,让模型倾向于选择高概率关键词的示例
- RULE 利用统计方法(Bonferroni校正)校准相关上下文
- 利用统计方法,将“5%概率存在错误上下文”这样的朴素要求通过统计运算转换成单个上下文相关度的硬阈值
- 视频检索中基于聚类的关键帧选择来提高多样性
相关性评估
- SSIM (Structural Similarity Index Measure)
最早用于图像领域,衡量两幅图像间的结构、亮度、对比度相似度。现在常用于多模态信息检索,例如图片和文本联合时的相似性计算。
- 比起传统的均方差等简单像素差,更符合人类对视觉感知的一致性判断,综合考虑亮度对比度等
- NCC (Normalized Cross-Correlation)
标准化互相关,常见于信号处理,也可以衡量不同模态数据间的相关强度。
- 衡量两个向量或数组的线性相关性
- BERTScore 利用BERT这样的深度语义模型计算文本间的语义相似度,比传统关键词对齐更关注上下文语义一致性
- 分层后处理:重排、相似度筛选、上下文窗口、合并、...
-
LDRE
结合多种特征(如caption描述、上下文语义、实体识别等),通过权重自适应集成,提高不同表示方式下的检索相关性适应能力
-
BM25等传统排名的集成
过滤机制
-
硬负样本挖掘:比起文本的硬负样本挖掘需要多处理跨模态的问题,如不同模态的bias等
- GME
- MM Embed
-
共识过滤、多向量过滤
- MuRAR
- ColPali
-
动态模态过滤
- 训练retriever判断哪部分是噪�声
- RAFT, Img2Loc, MAIN-RAG
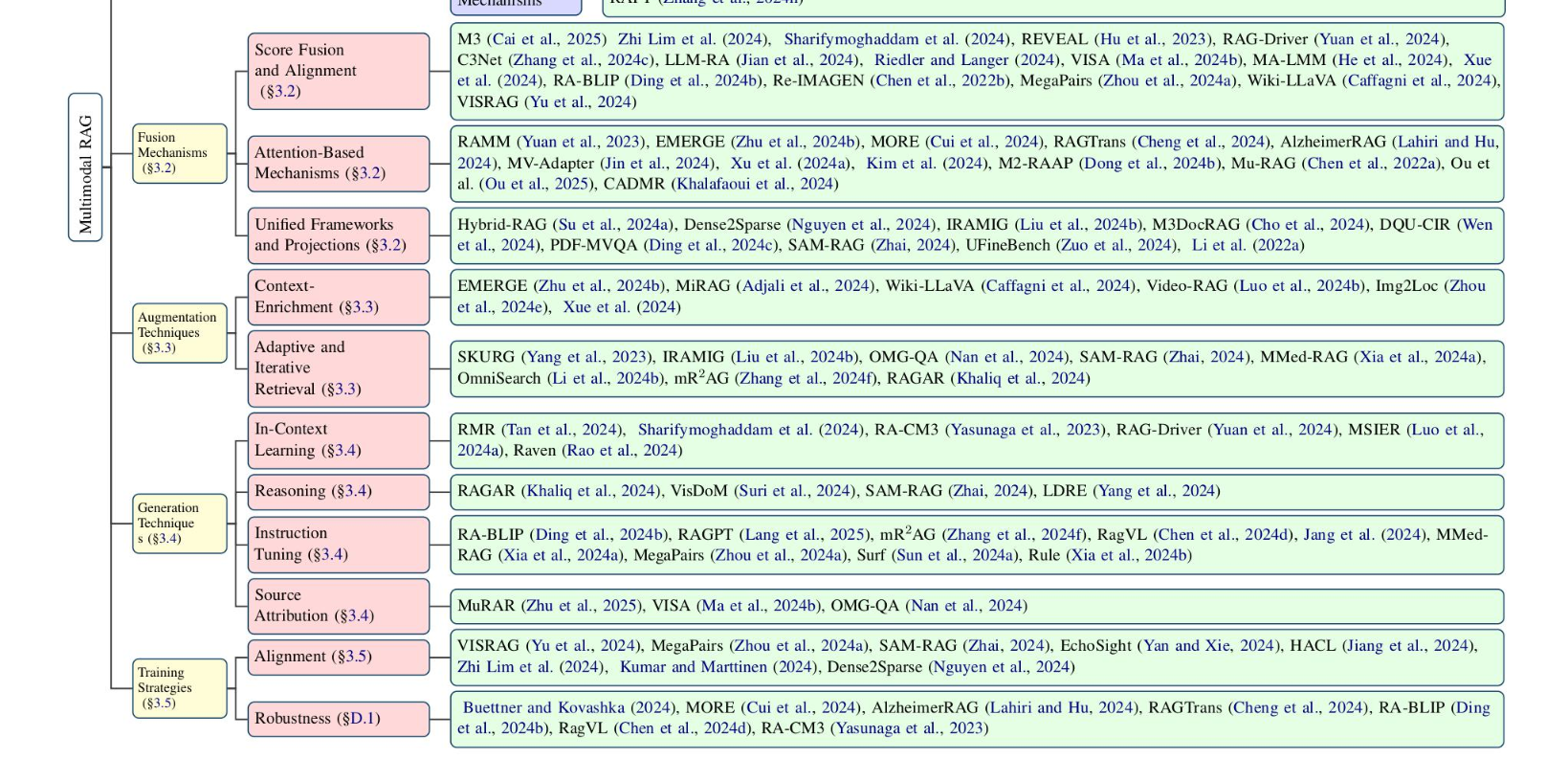
融合机制
分数融合和对齐
-
训练交叉编码器将多模态转换为文本格式
-
引入交错文本对,合并垂直多张few shot images(?)
-
CLIP分数融合,BLIP特征融合,嵌入到相同的空间
-
VISA 使用文档截图嵌入(DSE)模型,对齐文本查询和视觉文档表示
-
MA-LMM视频文本嵌入
-
LLM-RA 将文本和视觉嵌入连接成联合查询
-
...
注意力机制:
注意力方法动态加权跨模态交互,支持特定任务推理
EMERGE, MORE, Alzheimer RAG,RAMM,RAGTrans, MV-Adapter, M2-RAAP
统一的框架和预测
M3DocRAG : 多页文档展平为单个嵌入张量
PDF-MVQA 融合了基于感兴趣区域 (RoI) 和基于块 (CLIP) 的视觉语言模型
DQU-CIR 图像转换为复杂查询的文本标题以及将文本叠加到图像上来统一原始数据,然后通过 MLP 学习的权重融合嵌入
SAM-RAG生成图像的标题来对齐图像-文本模态
UFineBench 利用共享粒度解码器进行超精细文本人物检索
Dense2Sparse 投影,将来自 BLIP/ALBEF Li 等人 ( 2022a ) 等模型的密集嵌入转换为稀疏词汇向量,使用层归一化和概率扩展控制来优化存储和可解释性
增强技术
Context Enrichment
查询 重构为结构化检索请求, Video-RAG,EMERGE 整合实体关系和语义描述
Img2Loc 提示中包含数据库中最相似的和最不相似的点来让模型排除预测中不可信的位置
虽然说只是prompt工作,但想法似乎挺有趣,只是这样的作法能否比简单的几层MLP强呢?

动态检索
-
SKURG 查询复杂度决定跳数
-
MR2AG 动态评估和过滤
-
OmniSearch 分解问题
生成技术
-
In context learning
-
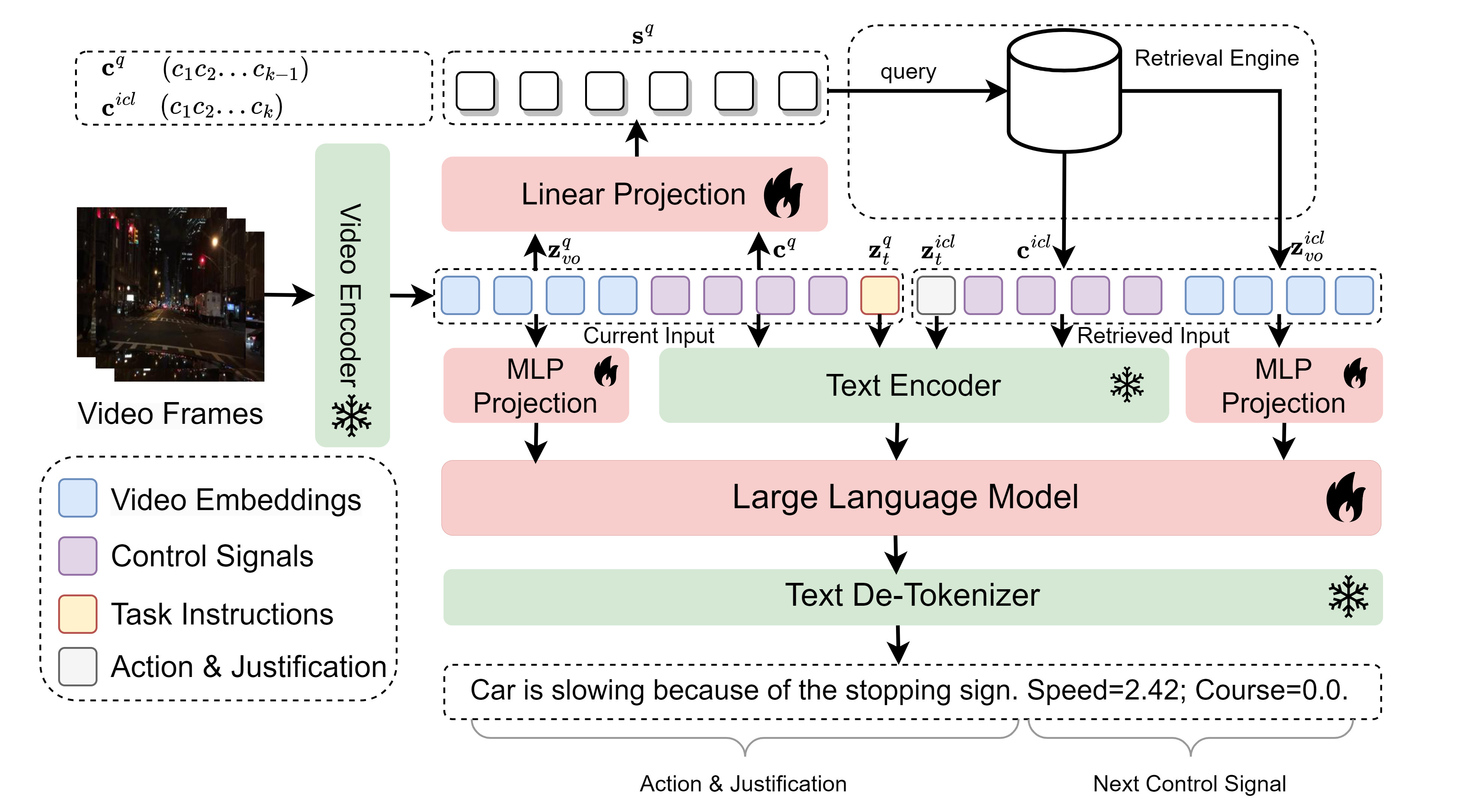
记忆数据 RAG-Driver(可解释的自动驾驶)
- 检索引擎 接收到当前驾驶场景(如视频帧和对应的车辆控制信号)后,先在专家示范的记忆库中检索出与当前最相似的历史驾驶样本。
- 多模态大语言模型处理
将检索到的样本与当前场景一同输入多模态大语言模型(MLLM),利用指令微调(Instruction Tuning),实现三项任务:
- 动作解释(Driving Action Explanation):输出当前行为的自然语言解释;
- 行为理由(Action Justification):对决策作出合理性说明;
- 控制信号预测(Control Signal Prediction):给出下一个动作的具体数值(如速度和转角)
-
-
融合上下文Fusion-in-Context Learning (没太看懂RAVEN这篇论文和融合上下文这一个比较早期的encoder-decoder模型的机制有什么关系)
-
Reasoning
- CoT RAGAR RAG链和RAG树,迭代方式优化事实核查
- VisDoM CoT和证据整理
- SAM-RAG 推理链和多阶段验证
指令调优:如mR2AG 用 mR2AG-IT的数据调优MLLM
来源归属
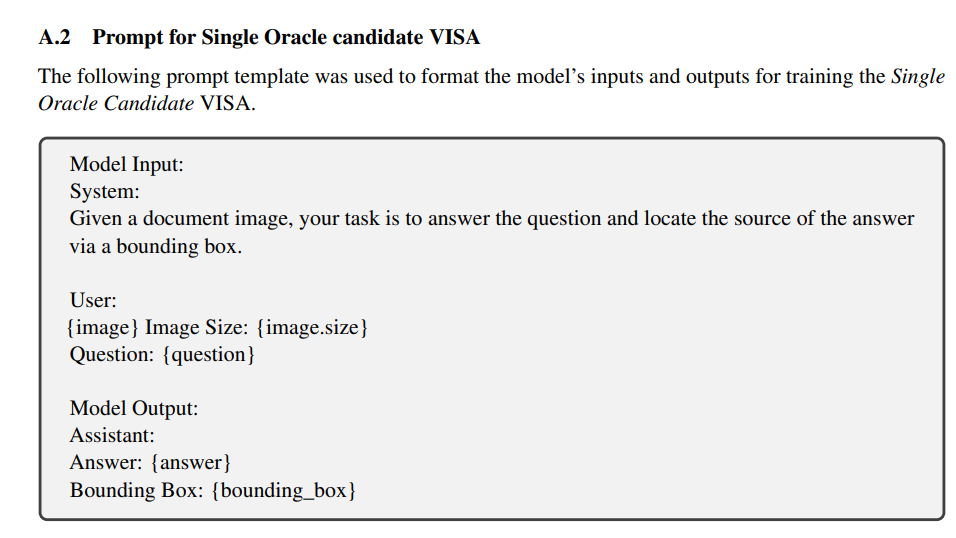
VISA 视觉来源归属
- 看了看他的论文,VLM直接输出边界框(也就是,输入为文档图片,输出为答案 + Box)的,再LoRA微调......
对齐
主要是对比学习:文档/图片/字幕...
噪声管理
RagVL 噪声注入训练,数据级别加负样本,token级别加Gauss噪声
RA-CM3 随机删除查询token做query dropout
MRAG解决的任务
- 图像字幕
- QA
- 事实验证
- 视觉叙事连贯性
- 图文检索
- .....
未来方向
泛化
-
领域自适应
-
模态偏差,过度依赖文本
-
可解释性
-
引用来源归属,在视觉/语音等模块更严重,难以识别出对应的小区域
-
多模态的对抗性扰动,误导性信息
推理
多模态融入KG
如何进行实体感知检索
位置敏感性
冗余检索
具身智能
长上下文,效率,可拓展
- 带图像的多页文档
- 视频这种超长上下文